Comment avons-nous vécu l'incident d’OVH du 10 mars: retour d'expérience
2021-03-24 | Florent DAMIENS

Comment avons-nous vécu l'incident d’OVH du 10 mars: retour d'expérience
Petit retour d'expérience concernant l'incendie d'un datacenter d'OVH en mars. Comment avons-nous été impacté et quels sont les processus que nous avons mis en place pour éviter la catastrophe.
Un peu de contexte
Le datacenter de Strasbourg d’OVH a été victime d’un violent incendie dans la nuit du 09 au 10 mars. L’intégralité du site, comprenant 4 datacenters, a été coupée, rendant inaccessibles plusieurs millions de sites et impactant tout autant d'entreprises dont la nôtre. Résultat : SBG2 est totalement détruit et les serveurs des 3 autres datacenters sont soit déplacés sur le site de Graveline ou Roubaix, soit en attente de redémarrage le temps de les nettoyer et de les vérifier. Une reprise totale de l’activité chez OVH n’est pas prévue avant plusieurs jours voire semaines.
Dans ce contexte assez chaotique, difficile d’anticiper un tel scénario. Beaucoup d'entreprises se sont retrouvées sans backup ni procédure pour relancer leur activité, bref sans PRA (Plan de Reprise d’Activité). Notre but est de partager nos différents outils, ainsi que la procédure que nous avons mise en place afin d’être le moins impactés par cette crise.
Présentation de nos outils
Nous avons personnalisé une multitude d’outils au fur et à mesure de leur utilisation. Dans le cadre de cette crise, nous en avons utilisé trois. Vous pouvez retrouver des articles plus techniques par rapport à ces outils sur le blog.
Nous utilisons un système d’alerting/monitoring avec Grafana. Tous nos serveurs sont reliés à cet outil et nous permettent d’avoir une vue sur les métriques des machines : RAM, CPU, stockage… En cas de plantage de service, de downtime ou de dépassement de seuil nous recevons, via PagerDuty, une alerte sur un channel Slack dédié au monitoring. Vous pouvez retrouver notre article dédié à l’installation de Grafana ici.
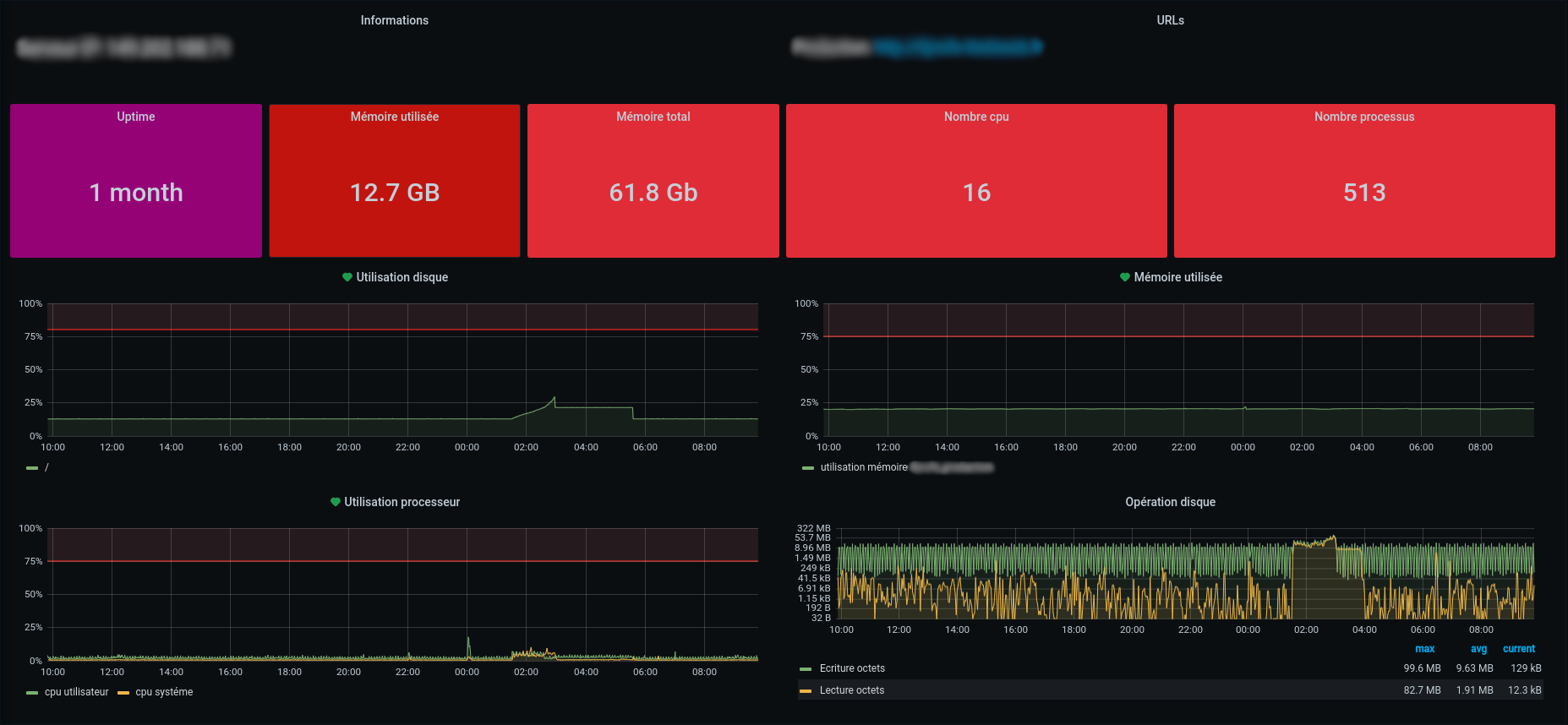
Le second outil est un système de provisioning de serveur. Il se base sur Chef. Nous avons personnalisé ce système ce qui nous permet aujourd’hui de configurer finement un serveur. De la gestion des Vhost en passant par la gestion du stockage (et des backups) mais aussi la gestion des services qui seront utilisés par l’application. En configurant un rôle qui contient toutes ces informations, nous pouvons monter une machine en quelques minutes. Vous pouvez retrouver notre article détaillé sur notre utilisation de Chef.
Pour finir cette présentation, notre système de déploiement est également automatisé et il est également beaucoup customisé. Il se base sur Capistrano et nous permet d’automatiser le déploiement d'applications utilisant Symfony, Wordpress, Drupal… Là aussi, nous pouvons déployer plusieurs environnements (QA, PREPROD, PROD) en quelques minutes.
Finalement, cette stacks d’outils automatisés nous a permis de sortir assez rapidement de cette crise.
Notre gestion de l’incident
Ce genre d'événement arrive, heureusement, assez rarement et permet de mettre en évidence les entreprises qui ont un plan d’action pour remettre en route leur activité. Au moment de cette crise, vous avez probablement entendu parler de PRA, c’est ce fameux plan d’action, un document où sont énumérés les risques possibles, les applications impactées, la gestion des sauvegardes et les priorités à tenir… Bref une de feuille de route dont l’objectif est de prendre en compte le maximum d’éventualités afin d’être le moins impacté possible et de reprendre rapidement l’activité.
Dans notre cas, un de nos techniciens a été chargé de remonter les 6 machines impactées. Notre système d’alerting nous a avertit d’un downtime des sites dans la nuit, nous avons donc pu prévenir les clients du sinistre au plus tôt. À partir de là, nous avons réalisé un état des lieux des backups des différents sites. Notre système de provisioning s'occupant de créer des backups quotidiennement et de les envoyer sur Amazon S3, aucune perte de données n'a été à déplorer, y compris au niveau des SQL. Nous avons ensuite listé et priorisé tous les environnements que nous devions remonter.
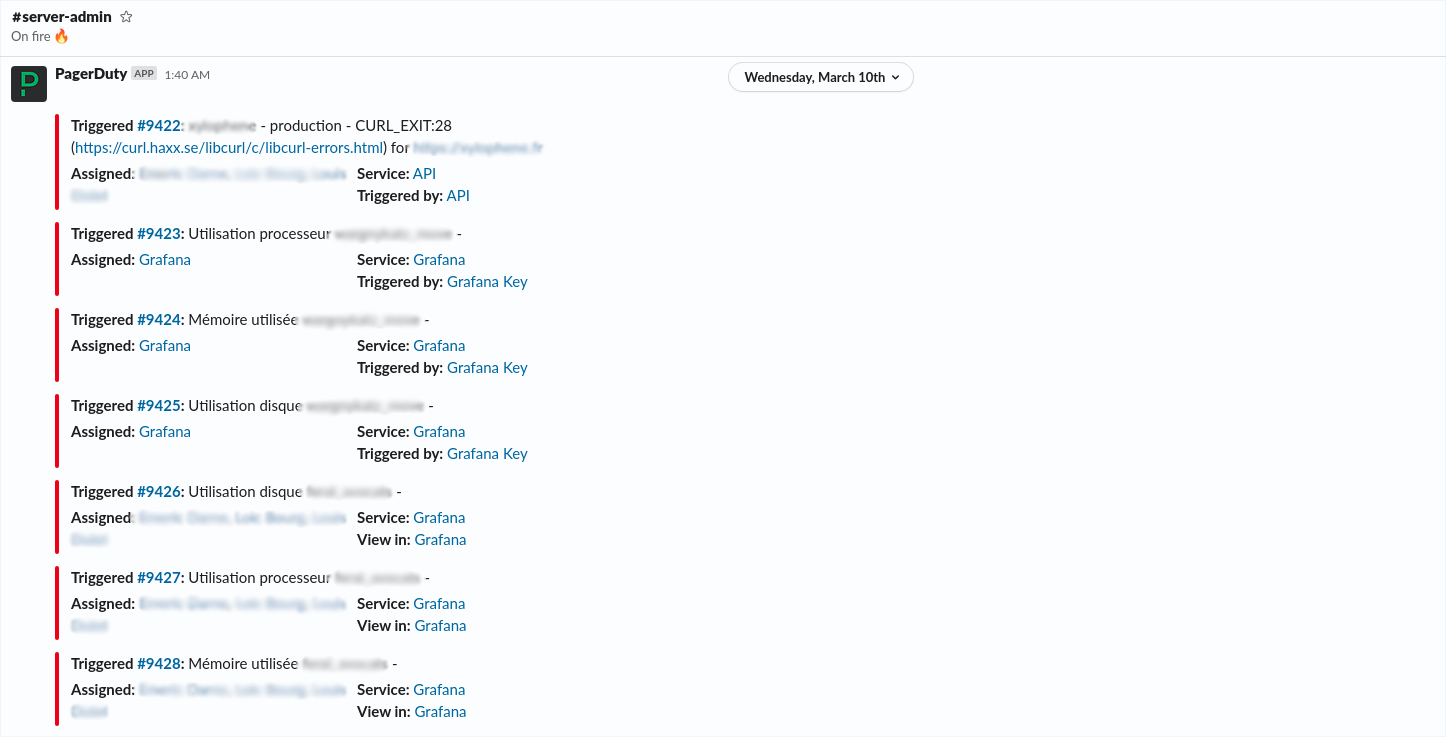
Nous avons malheureusement eu un problème important, notre serveur de provisioning est également parti en fumé dans l’incendie. Impossible donc de remonter les machines directement. La première étape a été de remonter cette machine via un backup en là ré-installant sur un serveur dans un autre datacenter d’OVH. Cette étape a été la plus complexe car la gestion de Chef serveur a changé entre la machine originale et la nouvelle version. Après une bonne journée pour remonter ce serveur et un problème de certificat plus tard, il fut temps de réinstaller les autres machines.
Nous avons réussi à récupérer les rôles des serveurs grâce aux backups des SQL, et relancer le provisionning des machines fraîchement créées. Une fois cette étape terminée l’objectif a été de déployer les applications manquantes via notre outil, réintégrer les données et prévenir les clients du retour de leur service.
Conclusion
Pour conclure, cette mésaventure nous aura coûté une journée de travail pour remonter le serveur de provisioning et environ 2h pour les autres machines. Même si toutes les entreprises ne réalisent pas un PRA, il est primordial pour un technicien de mettre en place des backups régulièrement et d’avoir connaissance des processus nécessaires au remontage de machines.
• Incendie OVH • OVH Strasbourg • PRA • Plan de Reprise d'Activité • 2021 • OVH